
News
· Mar 11, 2025
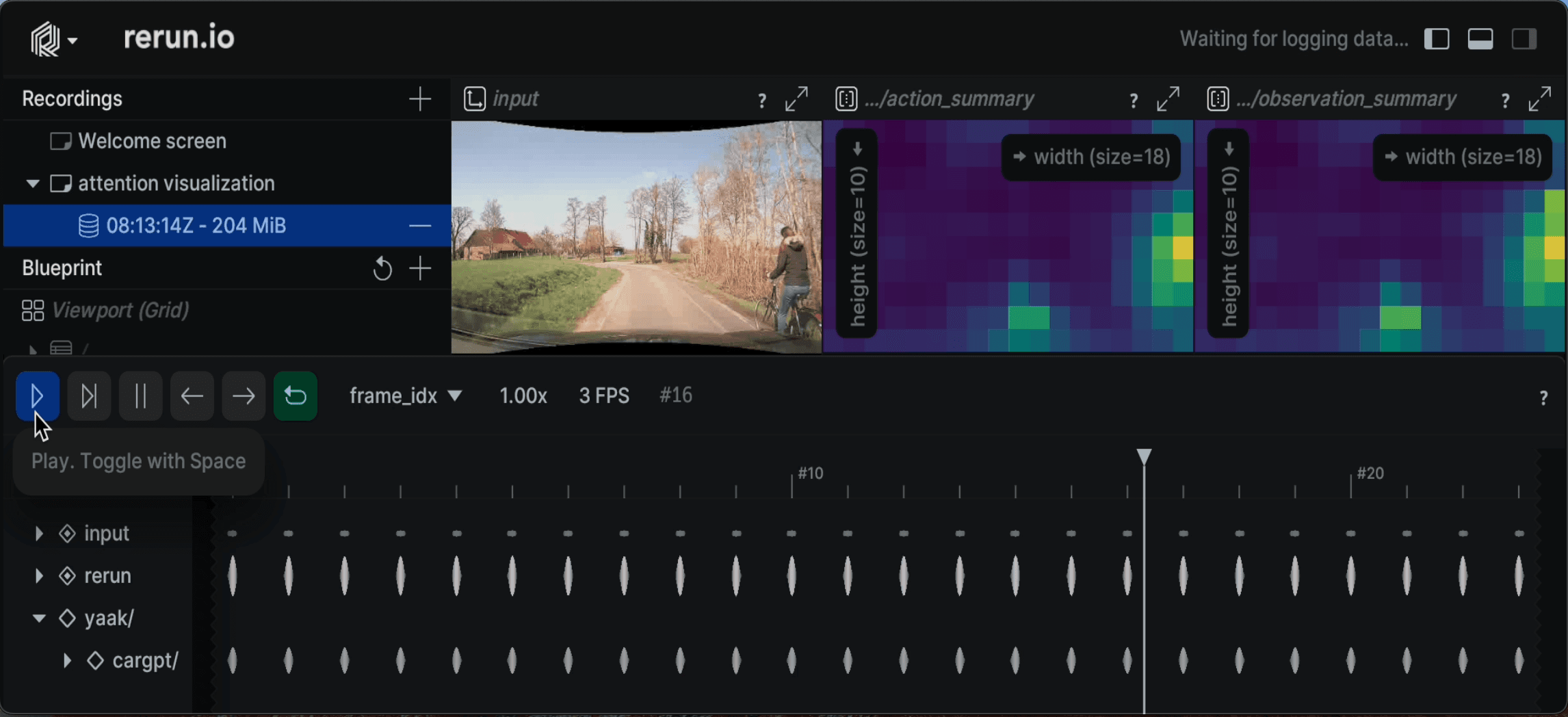
LeRobot goes to driving school
Yaak and Hugging Face are teaming up to create the world’s largest open-source, self-driving dataset: Learning to Drive (L2D).
Technology
· Oct 23, 2024
Building Spatial Intelligence - Part 2
While working with petabyte scale datasets from the automotive domain, we identified 4 key areas essential to building end-to-end (e2e) AI models for robotics: Logs, Discovery, Multimodal data, and Spatial intelligence.

Technology
· Oct 2, 2024
Building Spatial Intelligence - Part 1
Movement is essential to intelligence. The cycle of perceiving and acting is key to our understanding of the physical world around us: cleaning a tabletop, navigating an intersection, or moving household items. These seemingly trivial tasks hide a complex choreography of sensory-motor abilities in plain sight.

Technology
· Jul 19, 2023
Next action prediction with GPTs
In this blog, we extrapolate the idea of next-word prediction (given a partial sentence) to next-action prediction (given the context, e.g. image, sensor data). We found that a simple formulation doesn't work out of the box but rather requires careful understanding of state-action spaces and causality.

Technology
· Jun 27, 2023
A novel test for autonomy
We shed light on learning to drive and testing for human drivers within the context of current EU regulations. We hypothesize that training lessons and driving tests are a possible blueprint for a test of generalization for …